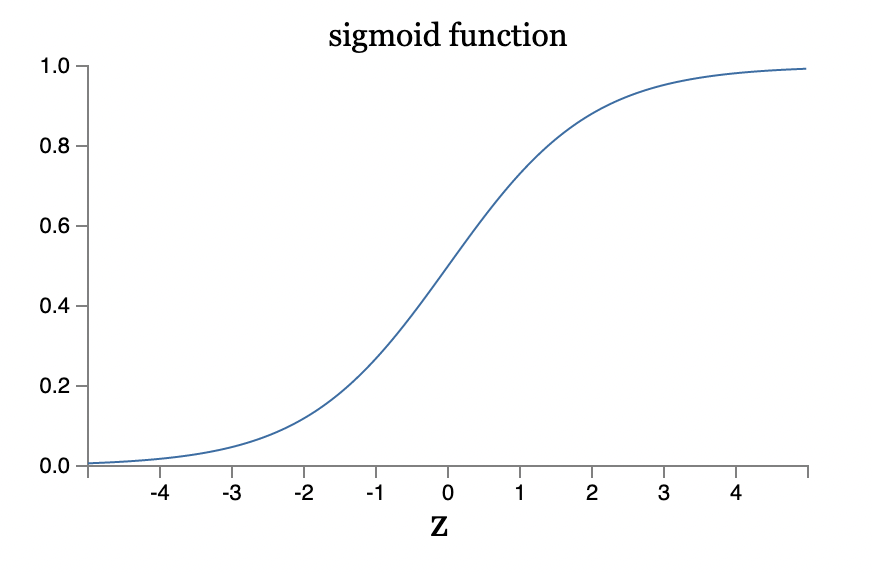
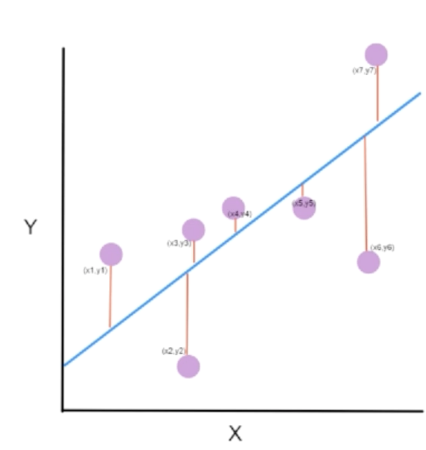
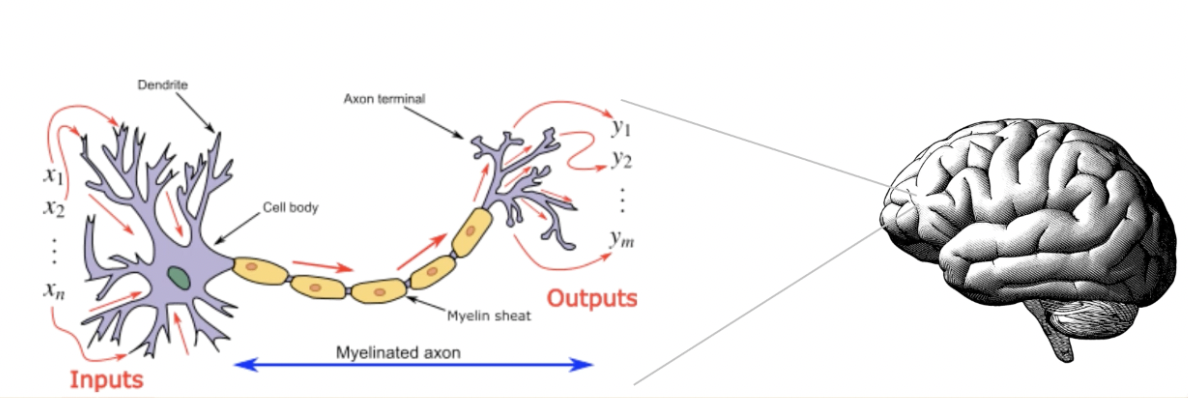
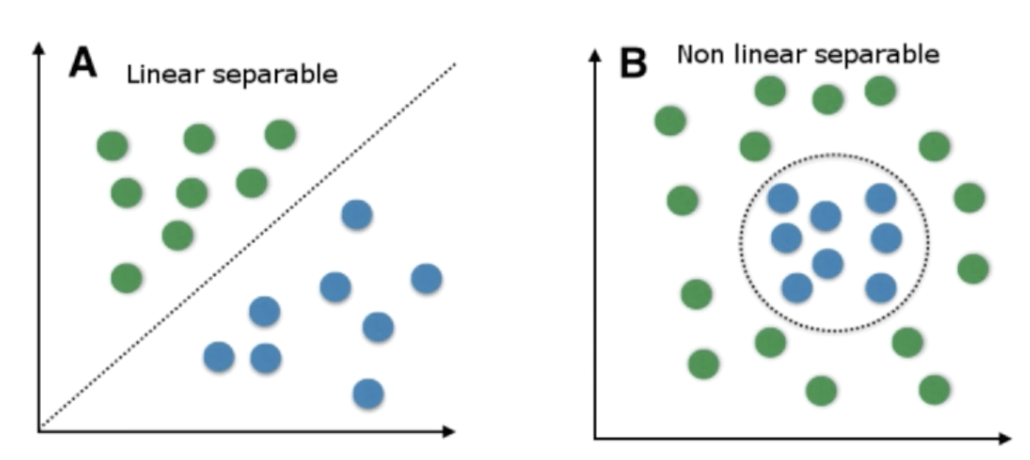
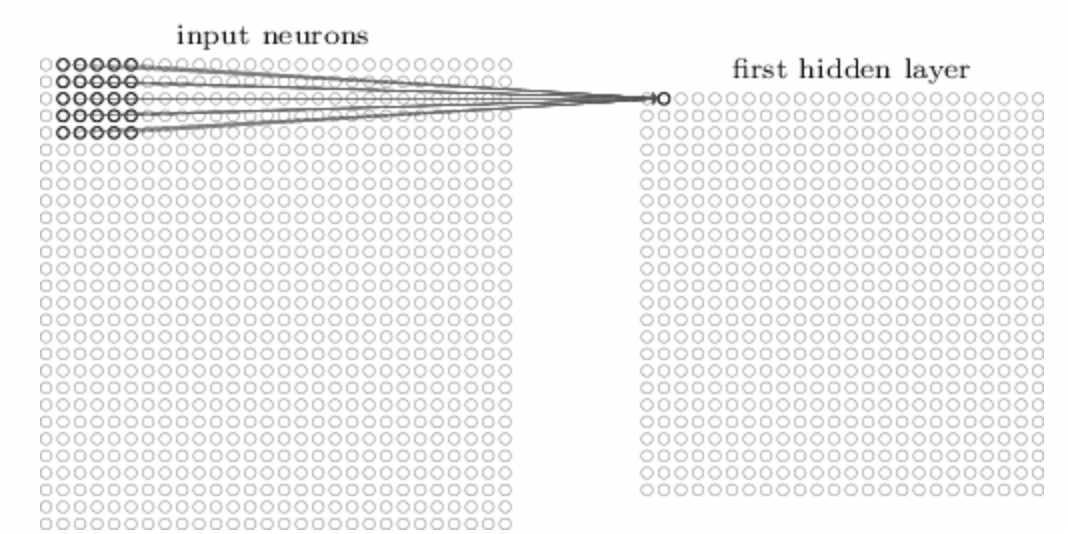
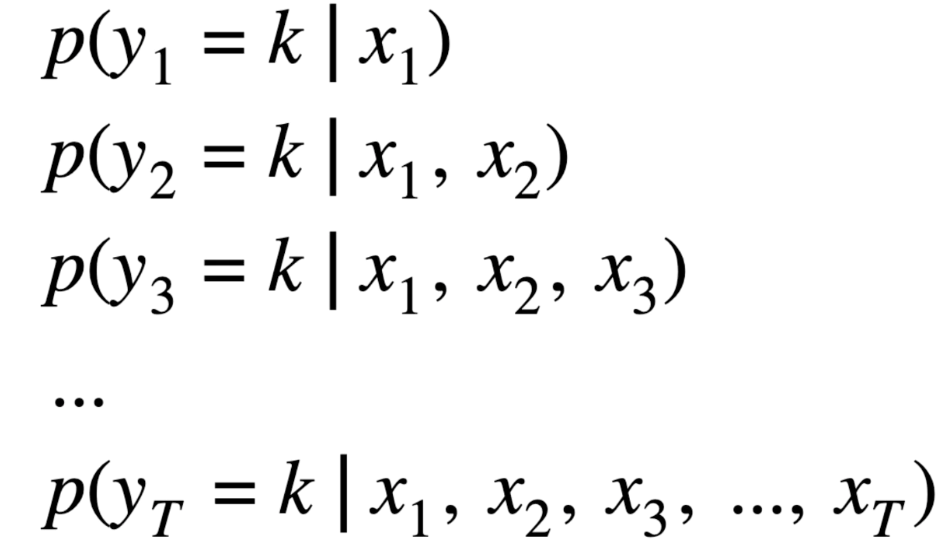Sigmoid neurons are similar to perceptrons, but modified so that small changes in their weights and bias cause only a small change in their output.
Those say that $\triangle output$ is a linear function of the changes $\triangle w_j$ and $\triangle b$ in the weights and bias. make it much easier to figure out how changing the weights and biases will change the output.
sigmoid function is defined by:
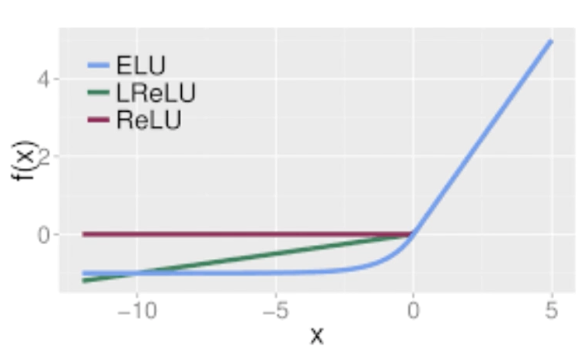
ReLU may be even more biological plausible than sigmoid;
In Tnesorflow 2.0
Is mostly an exercise in “API hunting”
The actual math isn’t written in code (by you)
Your job is to find the function that implements the math in question
tf.keras.layers.Dense(Output_size)
1
model = tf.keras.models.Sequential([ tf.keras.layers.Input(shape=(D,)), tf.keras.layers.Dense(1, activation='sigmoid')])
cost function
1
model.compile (optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
Accuracy
1
model.compile(optimizer='adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
Training / Fitting
1
r = model.fit (X_train, y_train, validation_data = (X_test, y_test), epochs=100)plt.plot(r.history['loss'],label='loss')plt.plot(r.history['val_loss'],label='val_loss')
To be conclude,
Prediction = Round( σ(Wx + b) )
Implemented with Keras Dense layer
compile() to specify optimizer (adam), loss (binary cross entropy), metrics(accuracy)
fit() returns a history object, so we can plot loss per iteration
TensorFlow done this for us by automatic differentitation
Tensorflow automatically finds the gradient of loss wrt all tour model weights
Tensorflow uses the gradients to train your model
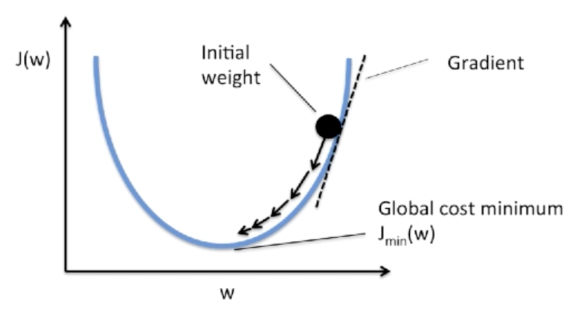
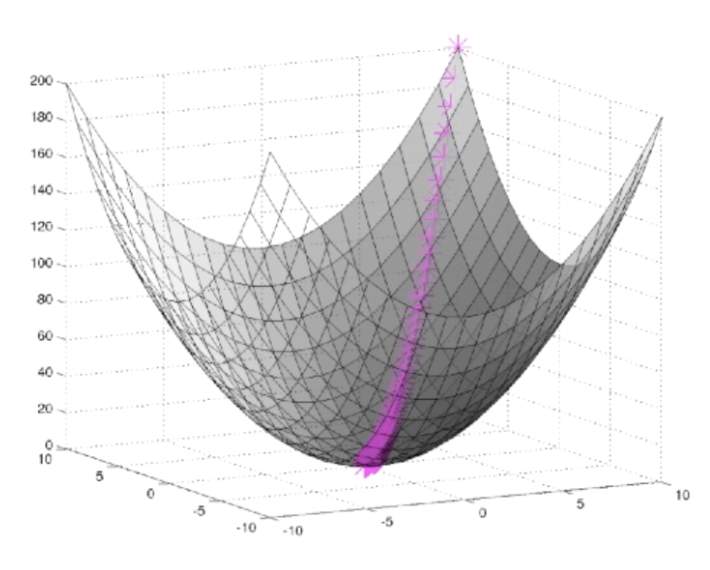
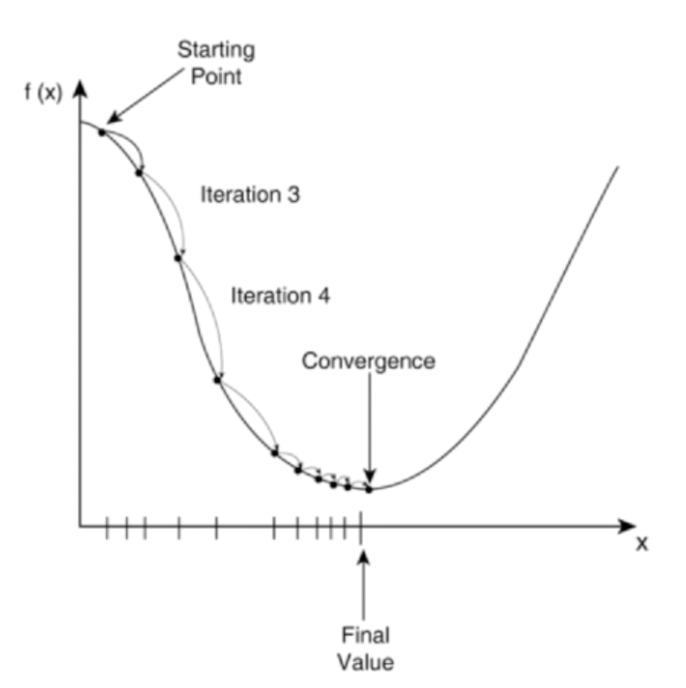
Gradient Descent
In most cases, it is not possible to solve for $anbla J=0$, using training iterative instead. (Linear Regression is the exception.)
gradient descent algorithm is inside the Keras fit function:
1 2 3 4 5 6
w,b = randomly initialized for epoch inrange (epochs): w = w - \eta * \nabla_w J b = b - \eta * \nabla_b J # \eta is called learning rate
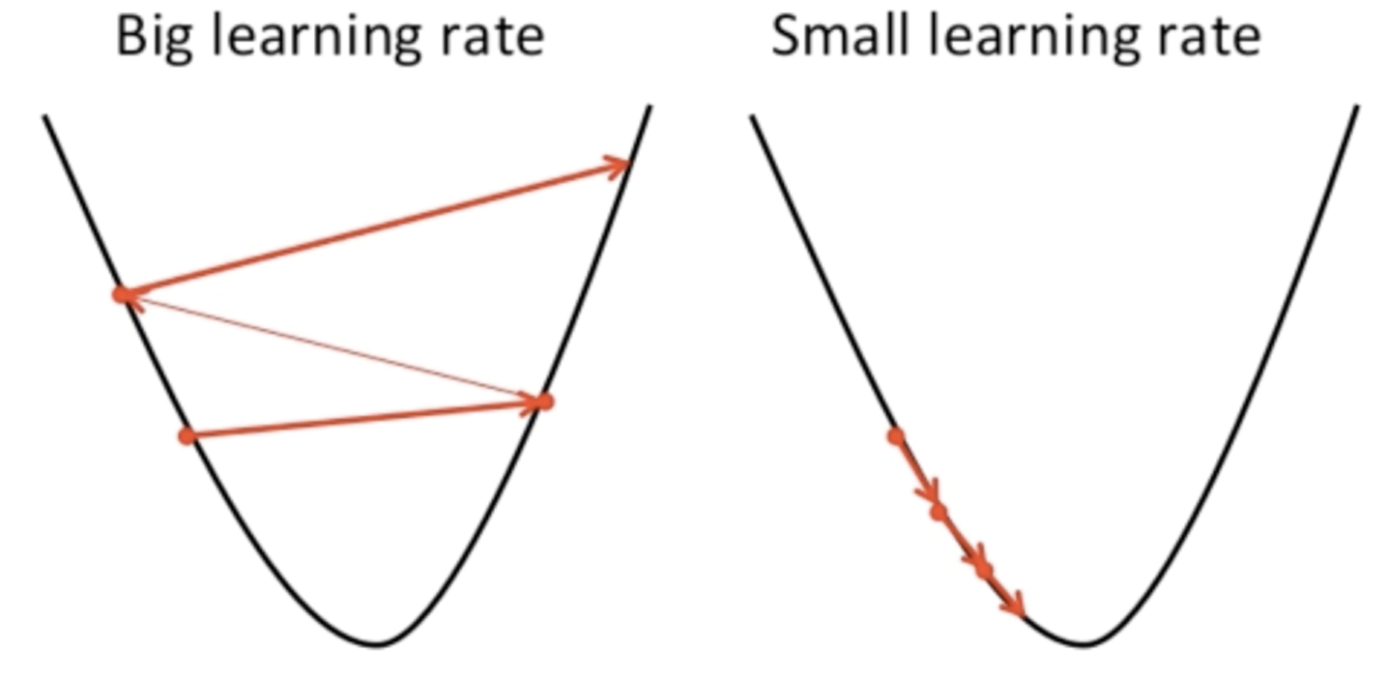
The aim of our traning algorithm will be to minimize the cost $C(w,b)$ as a fucntion of the weights and biases. In other words, we want to find a set of weights and biases which make the cost as small as possible.
Gradient descent can be viewed as a way of taking small steps in the direction which does the most to immediately decrease C.
Stochastic gradient descent(SGD) used to speed uop learning.
The idea is to estimate the gradient $\nabla C$ by computing $\nabla C_x$ for a small sample of randomly chosen training inputs. By averaging over this small sample it turns out that we can quickly get a good estimate of the true gradient $\nabla C$/
The Cauchy-Schwarz inequality:
for all vectors u and v of an inner product space, it is true that:
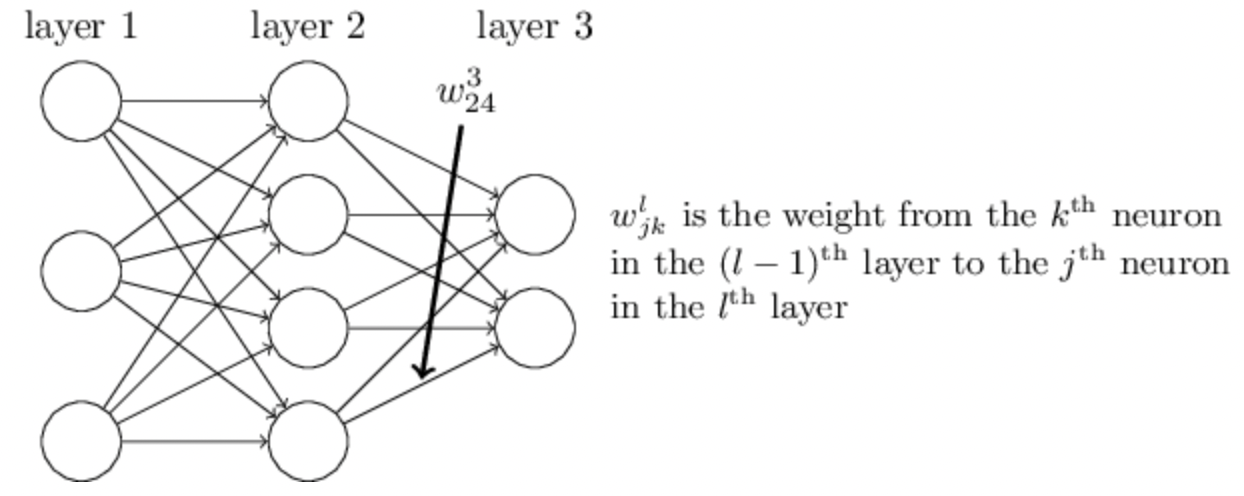
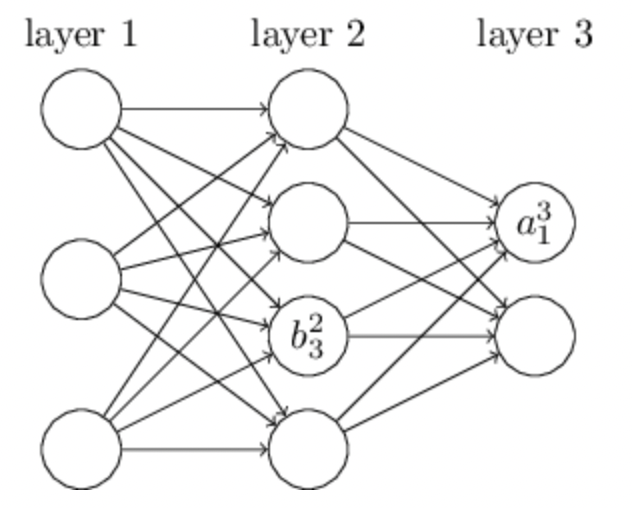
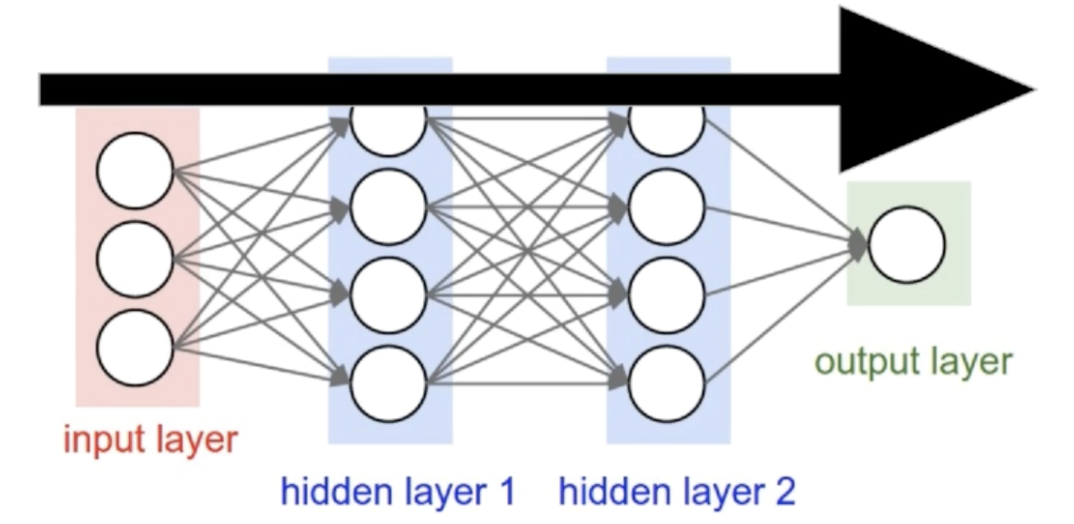
classNetwork(object): def__init__(self, sizes): self.num_layers = len(sizes) self.sizes = sizes self.biases = [np.random.randn(y,1) for y in sizes[1:]] self.weights= [np.random.randn(y,x) for x,y inzip(sizes[:-1], sizes[1:])] net = Network([2, 3, 1])
# Out: # The biases and weights in the Network object are all initialized randomly # using the Numpy np.random.randn function to generate Gaussian distributions with mean 0 and standard deviation 1 biases= [array([[-1.53072684], [-0.08241161], [-1.59648056]]), array([[-0.85710365]])] weights= [array([[ 1.08006753, -0.59936474], # 代表虚线 [-0.57578445, -0.50663782], [ 1.16481607, 0.06044497]]), array([[ 0.5560195 , -2.12356058, 2.19147343]])]
接下来,就要计算每一层的输出:
1 2
defsigmoid(z): return1.0/(1.0+np.exp(-z))
1 2 3 4 5
deffeedforward(self, a): """Return the output of the network if "a" is input.""" for b, w inzip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a
defSGD(self, training_data, epochs, mini_batch_size, eta, test_data=None): """Train the neural network using mini-batch stochastic gradient descent. The "training_data" is a list of tuples "(x, y)" representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory. If "test_data" is provided then the network will be evaluated against the test data after each epoch, and partial progress printed out. This is useful for tracking progress, but slows things down substantially.""" """eta is the learning rate. If the optional argument test_data is supplied, then the program will evaluate the network after each epoch of training, and print out partial progress. This is useful for tracking progress, but slows things down substantially.""" if test_data: n_test = len(test_data) n = len(training_data) for j in xrange(epochs): random.shuffle(training_data) #洗牌 mini_batches = [ training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] #for each mini_batch we apply a single step of gradient descent,which updates the network weights and biases according to a single iteration of gradient descent. for mini_batch in mini_batches: self.update_mini_batch(mini_batch, eta) if test_data: print"Epoch {0}: {1} / {2}".format( j, self.evaluate(test_data), n_test) else: print"Epoch {0} complete".format(j)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
defupdate_mini_batch(self, mini_batch, eta): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The "mini_batch" is a list of tuples "(x, y)", and "eta" is the learning rate.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: # the backpropagation algorithm,which is a fast way of computing the gradient of the cost function. delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb inzip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw inzip(nabla_w, delta_nabla_w)] self.weights =[w-(eta/len(mini_batch))*nw for w, nw inzip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb inzip(self.biases, nabla_b)]
An equation for the error $\delta^l$ in terms of the error in the next layer, $\delat^{l+1}$:
Differentiating, we obtain
Substituting back we obtain:
矩阵形式:
其中,$(w^{l+1})^T$ is the transpose of the weight matrix $w^{l+1}$ for the $(l+1)^{th}$ layer. 假定我们知道上一$l+1$层的误差$\delta^{l+1}$。When we apply the transpose weight matrix, $(w^{l+1})^T$, we can think intuitively of this as moving the error backward through the network, giving us some sort of meaure of the error at the output of the l layer.
后面MIT的课程上,通过forward propagation dual number 来求解。ODE关联,优化问题。都是梯度下架问题。在ODE问题中,用隐式算法,同样会涉及逆问题。最后,貌似都转化为同一个问题。
An equation for the rate of change of the cost with respect to any bias in the network:
通过这个公式,我们就获得了b的偏导数。
An equation for the rate of change of the cost with respect to any weight in the net work:
When $a_in$ is small, the gradient terms ${\partial C \over \partial w}$ will also tend to be small, it learns slowly. — low-activation
Besides, consider the term $\sigma’(z_j^L)$ become very flat when approach to 0 or 1, it also learns slowly. — saturated
The backprogation algorithm
Input x: Set the corresponding activation $a^1$ for the input layer.
Feedforward: For each l=2,3,…,L compute $z^l = w^l a^{l-1}+b^l$ and $a^l=\sigma(z^l)$.
Output error $\delta^L$: Compute the vector $\delta^L = \nabla_a C \odot \sigma’(z^L).$
Backpropagate the error: For each l = L-1,L-2,…,2 compute
Output: The gradient of the cost function is given by
The backprogation algorithm with a set of training examples
计算过程不变,只不过最终梯度下架为计算的平均值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
classNetwork(object): ... defupdate_mini_batch(self, mini_batch, eta): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The "mini_batch" is a list of tuples "(x, y)", and "eta" is the learning rate.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb inzip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw inzip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw inzip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb inzip(self.biases, nabla_b)]
classNetwork(object): ... defbackprop(self, x, y): """Return a tuple "(nabla_b, nabla_w)" representing the gradient for the cost function C_x. "nabla_b" and "nabla_w" are layer-by-layer lists of numpy arrays, similar to "self.biases" and "self.weights".""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w inzip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w)
...
defcost_derivative(self, output_activations, y): """Return the vector of partial derivatives \partial C_x / \partial a for the output activations.""" return (output_activations-y)
defsigmoid_prime(z): """Derivative of the sigmoid function.""" return sigmoid(z)*(1-sigmoid(z))
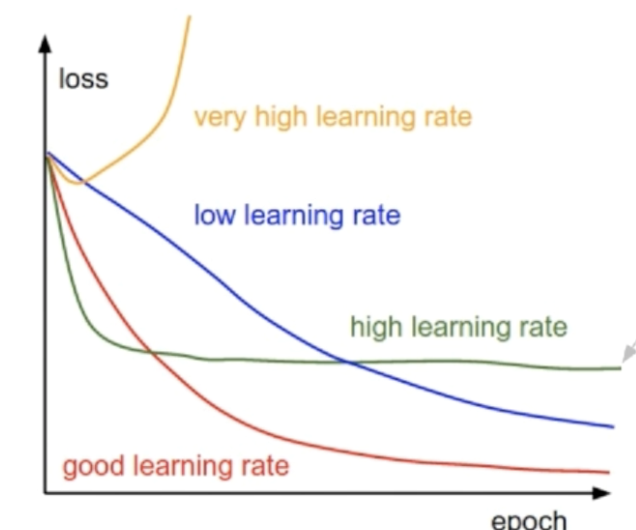
learning rate is low, means that the partial derivatives of the cost function, $\partial C/\partial w$ and $\partial C / \partial b$ is small.
Better choice of cost function: the cross-entropy
对单个输入的神经网络来说,
则带来的好处是:
训练误差越大,则学习速度越快!
“Regularization” methods (L1 and L2 regularization, dropout, and artificial expansion of the traning data)
过拟合问题。
regularized cross-entropy
The effect of regularization is to make it so the network prefers to learn small weights, all other things being equal. Regularization can be viewed as a way of compromising between finding small weights and minimizing the original cost function.
L1 regularization
相比L2 regularization,
In both expressions, the effect of regularization is to shrink the weights. This accords with our intuition that both kinds of regularization penalize large weights(罚函数)。In L1 regularization, the weights shrink by a constant amount toward 0. In L2 regularization, the weights shrink by an amount which is proportion to w. And so when a particular weight has a large magnitude, |w|, L1 regularization shrinks the weight much less than L2 regularization does. By contrast, when |w| is small, L1 regularization shrinks the weight much more than L2 regularization. z最终
"""network2.py ~~~~~~~~~~~~~~ An improved version of network.py, implementing the stochastic gradient descent learning algorithm for a feedforward neural network. Improvements include the addition of the cross-entropy cost function, regularization, and better initialization of network weights. Note that I have focused on making the code simple, easily readable, and easily modifiable. It is not optimized, and omits many desirable features. """
#### Libraries # Standard library import json import random import sys
# Third-party libraries import numpy as np
#### Define the quadratic and cross-entropy cost functions
classQuadraticCost(object):
@staticmethod # just as ordinary but now pass self deffn(a, y): """Return the cost associated with an output ``a`` and desired output ``y``. """ return0.5*np.linalg.norm(a-y)**2
@staticmethod defdelta(z, a, y): """Return the error delta from the output layer.""" return (a-y) * sigmoid_prime(z)
classCrossEntropyCost(object):
@staticmethod deffn(a, y): """Return the cost associated with an output ``a`` and desired output ``y``. Note that np.nan_to_num is used to ensure numerical stability. In particular, if both ``a`` and ``y`` have a 1.0 in the same slot, then the expression (1-y)*np.log(1-a) returns nan. The np.nan_to_num ensures that that is converted to the correct value (0.0). """ return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))
@staticmethod defdelta(z, a, y): """Return the error delta from the output layer. Note that the parameter ``z`` is not used by the method. It is included in the method's parameters in order to make the interface consistent with the delta method for other cost classes. """ return (a-y)
#### Main Network class classNetwork(object):
def__init__(self, sizes, cost=CrossEntropyCost): """The list ``sizes`` contains the number of neurons in the respective layers of the network. For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing 2 neurons, the second layer 3 neurons, and the third layer 1 neuron. The biases and weights for the network are initialized randomly, using ``self.default_weight_initializer`` (see docstring for that method). """ self.num_layers = len(sizes) self.sizes = sizes self.default_weight_initializer() self.cost=cost
defdefault_weight_initializer(self): """Initialize each weight using a Gaussian distribution with mean 0 and standard deviation 1 over the square root of the number of weights connecting to the same neuron. Initialize the biases using a Gaussian distribution with mean 0 and standard deviation 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers. """ self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x)/np.sqrt(x) for x, y inzip(self.sizes[:-1], self.sizes[1:])]
deflarge_weight_initializer(self): """Initialize the weights using a Gaussian distribution with mean 0 and standard deviation 1. Initialize the biases using a Gaussian distribution with mean 0 and standard deviation 1. Note that the first layer is assumed to be an input layer, and by convention we won't set any biases for those neurons, since biases are only ever used in computing the outputs from later layers. This weight and bias initializer uses the same approach as in Chapter 1, and is included for purposes of comparison. It will usually be better to use the default weight initializer instead. """ self.biases = [np.random.randn(y, 1) for y in self.sizes[1:]] self.weights = [np.random.randn(y, x) for x, y inzip(self.sizes[:-1], self.sizes[1:])]
deffeedforward(self, a): """Return the output of the network if ``a`` is input.""" for b, w inzip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a
defSGD(self, training_data, epochs, mini_batch_size, eta, lmbda = 0.0, evaluation_data=None, monitor_evaluation_cost=False, monitor_evaluation_accuracy=False, monitor_training_cost=False, monitor_training_accuracy=False): """Train the neural network using mini-batch stochastic gradient descent. The ``training_data`` is a list of tuples ``(x, y)`` representing the training inputs and the desired outputs. The other non-optional parameters are self-explanatory, as is the regularization parameter ``lmbda``. The method also accepts ``evaluation_data``, usually either the validation or test data. We can monitor the cost and accuracy on either the evaluation data or the training data, by setting the appropriate flags. The method returns a tuple containing four lists: the (per-epoch) costs on the evaluation data, the accuracies on the evaluation data, the costs on the training data, and the accuracies on the training data. All values are evaluated at the end of each training epoch. So, for example, if we train for 30 epochs, then the first element of the tuple will be a 30-element list containing the cost on the evaluation data at the end of each epoch. Note that the lists are empty if the corresponding flag is not set. """ if evaluation_data: n_data = len(evaluation_data) n = len(training_data) evaluation_cost, evaluation_accuracy = [], [] training_cost, training_accuracy = [], [] for j in xrange(epochs): random.shuffle(training_data) mini_batches = [ training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] for mini_batch in mini_batches: self.update_mini_batch( mini_batch, eta, lmbda, len(training_data)) print"Epoch %s training complete" % j if monitor_training_cost: cost = self.total_cost(training_data, lmbda) training_cost.append(cost) print"Cost on training data: {}".format(cost) if monitor_training_accuracy: accuracy = self.accuracy(training_data, convert=True) training_accuracy.append(accuracy) print"Accuracy on training data: {} / {}".format( accuracy, n) if monitor_evaluation_cost: cost = self.total_cost(evaluation_data, lmbda, convert=True) evaluation_cost.append(cost) print"Cost on evaluation data: {}".format(cost) if monitor_evaluation_accuracy: accuracy = self.accuracy(evaluation_data) evaluation_accuracy.append(accuracy) print"Accuracy on evaluation data: {} / {}".format( self.accuracy(evaluation_data), n_data) print return evaluation_cost, evaluation_accuracy, \ training_cost, training_accuracy
defupdate_mini_batch(self, mini_batch, eta, lmbda, n): """Update the network's weights and biases by applying gradient descent using backpropagation to a single mini batch. The ``mini_batch`` is a list of tuples ``(x, y)``, ``eta`` is the learning rate, ``lmbda`` is the regularization parameter, and ``n`` is the total size of the training data set. """ nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb inzip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw inzip(nabla_w, delta_nabla_w)] self.weights = [(1-eta*(lmbda/n))*w-(eta/len(mini_batch))*nw #L2 for w, nw inzip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb inzip(self.biases, nabla_b)]
defbackprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforward activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w inzip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass delta = (self.cost).delta(zs[-1], activations[-1], y) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w)
defaccuracy(self, data, convert=False): """Return the number of inputs in ``data`` for which the neural network outputs the correct result. The neural network's output is assumed to be the index of whichever neuron in the final layer has the highest activation. The flag ``convert`` should be set to False if the data set is validation or test data (the usual case), and to True if the data set is the training data. The need for this flag arises due to differences in the way the results ``y`` are represented in the different data sets. In particular, it flags whether we need to convert between the different representations. It may seem strange to use different representations for the different data sets. Why not use the same representation for all three data sets? It's done for efficiency reasons -- the program usually evaluates the cost on the training data and the accuracy on other data sets. These are different types of computations, and using different representations speeds things up. More details on the representations can be found in mnist_loader.load_data_wrapper. """ if convert: results = [(np.argmax(self.feedforward(x)), np.argmax(y)) for (x, y) in data] else: results = [(np.argmax(self.feedforward(x)), y) for (x, y) in data] returnsum(int(x == y) for (x, y) in results)
deftotal_cost(self, data, lmbda, convert=False): """Return the total cost for the data set ``data``. The flag ``convert`` should be set to False if the data set is the training data (the usual case), and to True if the data set is the validation or test data. See comments on the similar (but reversed) convention for the ``accuracy`` method, above. """ cost = 0.0 for x, y in data: a = self.feedforward(x) if convert: y = vectorized_result(y) cost += self.cost.fn(a, y)/len(data) cost += 0.5*(lmbda/len(data))*sum( np.linalg.norm(w)**2for w in self.weights) return cost
defsave(self, filename): """Save the neural network to the file ``filename``.""" data = {"sizes": self.sizes, "weights": [w.tolist() for w in self.weights], "biases": [b.tolist() for b in self.biases], "cost": str(self.cost.__name__)} f = open(filename, "w") json.dump(data, f) f.close()
#### Loading a Network defload(filename): """Load a neural network from the file ``filename``. Returns an instance of Network. """ f = open(filename, "r") data = json.load(f) f.close() cost = getattr(sys.modules[__name__], data["cost"]) net = Network(data["sizes"], cost=cost) net.weights = [np.array(w) for w in data["weights"]] net.biases = [np.array(b) for b in data["biases"]] return net
#### Miscellaneous functions defvectorized_result(j): """Return a 10-dimensional unit vector with a 1.0 in the j'th position and zeroes elsewhere. This is used to convert a digit (0...9) into a corresponding desired output from the neural network. """ e = np.zeros((10, 1)) e[j] = 1.0 return e
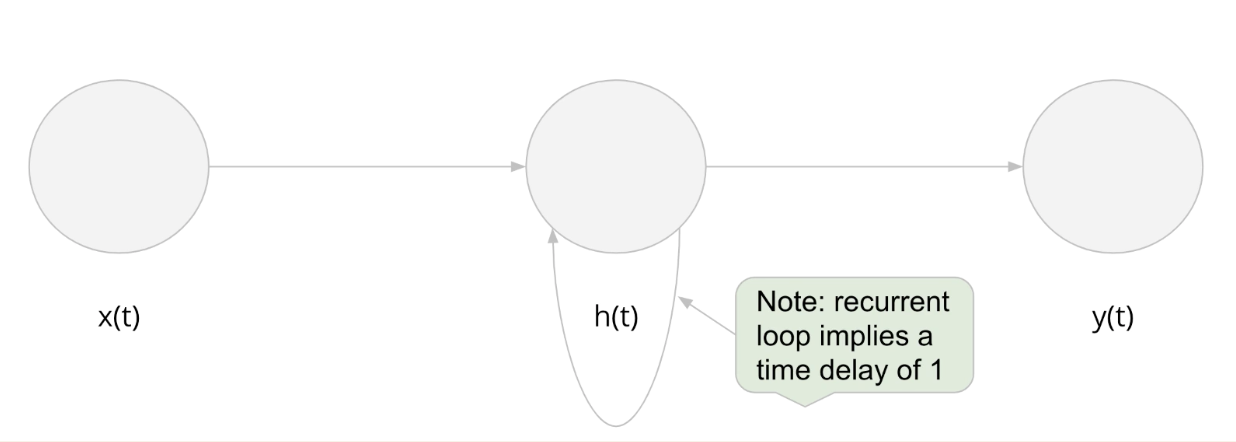
A recurrent neural network is a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior. Derived from feedforward neural networks, RNNs can use their internal state to process variable length sequences of inputs. This makes them applicable to tasks such as unsegmented, connected handwriting recognition or speech recognition.
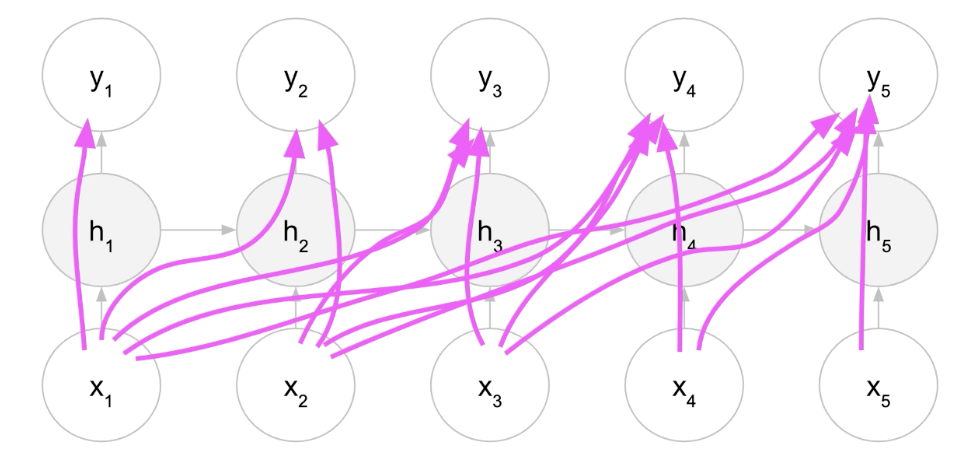
The main use of RNNs are when using google or Facebook these interfaces are able to predict the next word that you are about to type. RNNs have loops to allow information to persist. This reduces the complexity of parameters, unlike other neural networks. These neural nets are considered to be fairly good for modeling sequence data. RNNs keep track of a hidden state, that encodes information about the history of the system dynamics.
RNNs have the potential to overcome these scalability problems and be applied to high-dimensional spatio-temporal dynamics.
Recurrent neural networks are a linear architectural variant of recursive networks. They have a “memory” thus it differs from other neural networks. This memory remembers all the information about, what has been calculated in the previous state. It uses the same parameters for each input as it performs the same task on all the inputs or hidden layers to produce the output.
One of the biggest uniqueness RNNs have is “UAP- Universal Approximation Property” thus they can approximate virtually any dynamical system. This unique property forces us to say recurrent neural networks have something magical about them.
RNNs model has been proven to perform extremely well on temporal data. It has several variants including LSTMs (long short-term memory), GRUs (gated recurrent unit) and Bidirectional RNNs. Building models for natural language, audio files, and other sequence data got a lot easier with sequence algorithms.
This problem sent the major set back for RNNs to get popularity. Values in RNNs can explode or vanish due to a simple reason for remembering previous values. Previous values are good enough to confuse them and cause current values to keep increasing or decreasing & take-over algorithm. Indefinite loops get formed that brings whole network halt.
For example, neurons might get stuck in the loop where it keeps multiplying the previous number to new number which can go to infinity if all numbers are more than one or get stuck at zero if any number is zero.
If the weight is small, multiply it all the time, it will become small. Otherwise it will become very large.这样深度神经网络的训练也会失效。从深度网络的角度来讲,不同的层学习的速度差异很大,表现为网络中靠近输出的层学习的情况很好,靠近输入的层学习的很慢,有时甚至训练了很久,前几层的权值和刚开始随机初始化的值差不多。因此,梯度消失、爆炸,其根本原因在于反向传播训练法则backpropagation (BPTT)**,属于先天不足。
LSTMs employ gates that effectively remember and forget information thus alleviating the problem of vanishing gradients,可以缓解Vanishing and Exploding Gradient Problem。复杂的门可以接下来更新的时候“记住”前几次训练的“残留记忆”。
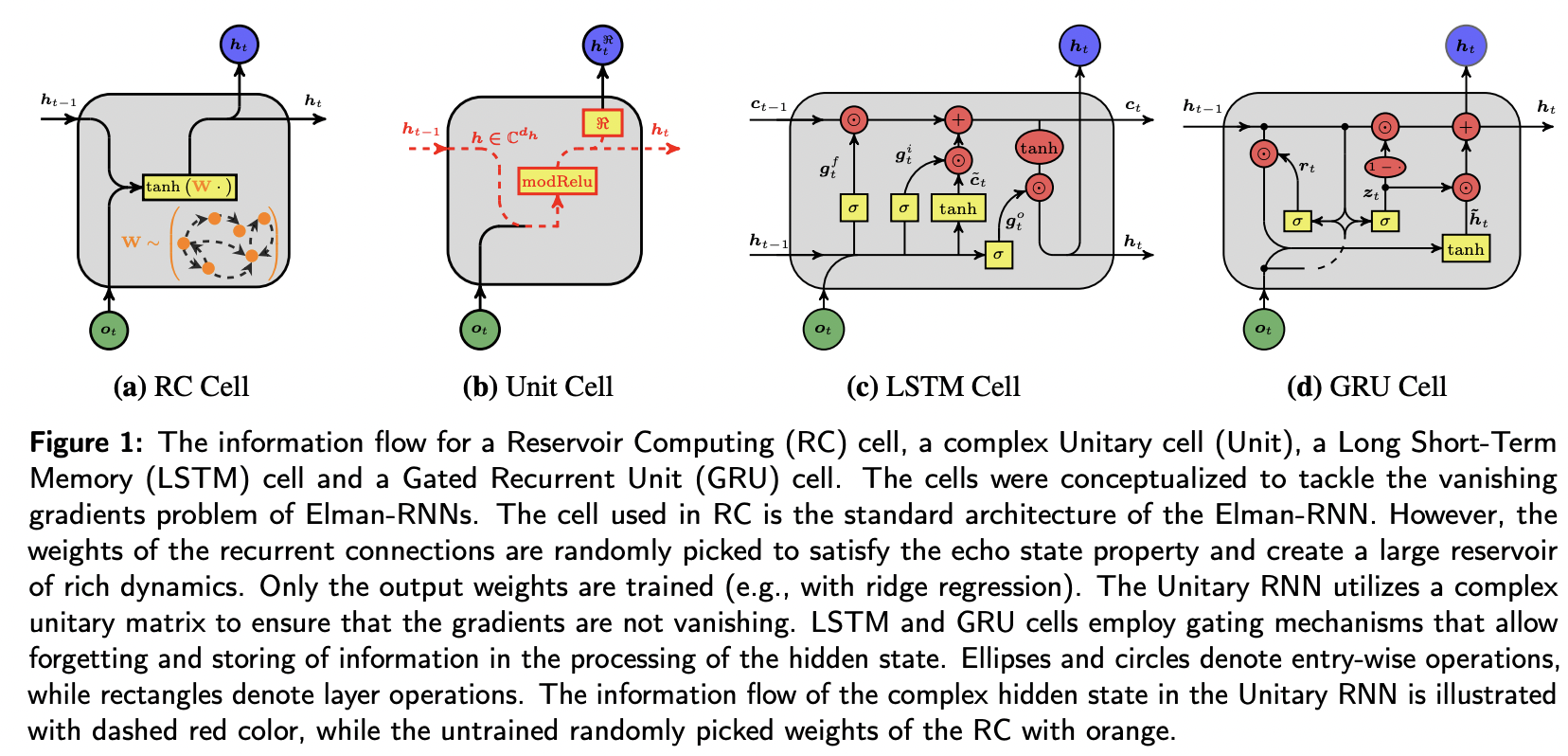
$$ 有点像电路板,gtf, gti, gto分别代表forget, input, output gates. ot is the observable input at time t, ht is the hidden state, ct is the cell state, W is weight matrices, b is biases. The symbol ⊙ denotes the element-wise product. δ is Sigmoid function. The dimension of the hidden state dh (number of hidden units) controls the capacity of the cell to encode history information. The hidden-to-output functional form fho is given by a linear layer: ôt + 1 = Woht, Wo ∈ Rd0 × dh
Reservior Computing
Reservoir computing is a framework for computation derived from recurrent neural network theory that maps input signals into higher dimensional computational spaces through the dynamics of a fixed, non-linear system called a reservoir.[1] After the input signal is fed into the reservoir, which is treated as a “black box,” a simple readout mechanism is trained to read the state of the reservoir and map it to the desired output.[1] The first key benefit of this framework is that training is performed only at the readout stage, as the reservoir dynamics are fixed.[1] The second is that the computational power of naturally available systems, both classical and quantum mechanical, can be utilized to reduce the effective computational cost.[2]
建模方法
机器学习预测时间序列。给定等间隔1/trianglet采样,可观测序列o ∈ Rdo ,{o1, …, oT}。输入前一个时间点的状态ht ∈ Rdh. ht = fhh(ot, ht − 1), ôt + 1 = fho(ht) fhh is hidden-to-hidden mapping, fho is the hidden-to-output mapping. 下面这四种模型都是这种结构,只是对f的实现和参数有所差异。参见:4